하이퍼바이저(Hypervisor)는 하나의 물리적 컴퓨터에서 여러 개의 가상 머신(VM, Virtual Machine)을 실행할 수 있게 해주는 소프트웨어입니다. 이를 통해 각 가상 머신은 독립된 운영 체제를 실행할 수 있으며, 하드웨어 자원을 공유합니다. 하이퍼바이저는 가상 머신과 실제 하드웨어 사이의 중재자 역할을 하며, 가상화 기술의 핵심 요소입니다.
Container 정의
컨테이너(Container)는 애플리케이션과 그 실행에 필요한 라이브러리, 의존성, 설정 파일 등을 하나의 독립된 단위로 묶어 운영 체제의 커널을 공유하면서도 서로 격리된 환경에서 실행되도록 하는 기술입니다. 컨테이너는 애플리케이션과 그 환경을 패키지화하기 때문에, 개발 환경에서 테스트 환경, 그리고 프로덕션 환경까지 동일하게 실행될 수 있습니다. "Write Once, Run Anywhere"의 개념을 실현 합니다.
Hypervisor 와 Container 비교
컨테이너는 도커라는 베이스 위에 소스코드 이미지가 실행되어서 각각 독립 된 상태로 띄어진다. 그리고 가볍다. (각각 독립 된 상태이기 때문에 서로에게 영향을 주지 않는다.)
가상머신은 하이퍼바이저 위에 각각의 가상머신이 각각 독립 된 상태로 실행된다. 각각의 가상머신은 OS 등 세팅이 되기 때문에 무거운 상태이다. 그래서 하나하나가 무겁다.
컨테이너는 가상머신을 만들지 않아도 되는 이미지를 실행만 하면 되는 것이기 때문에 가몁고 scale out과 배포에 큰 장점이 있다.
그래서 컨테이너는 필요할 때 언제든 빠르게 추가할 수 있다.
컨테이너는 하나의 OS 커널을 공유하기 때문에 각각이 완전한 격리가 이루어지지 않기 때문에 보안 이슈가 있을 수 있다. 반면 하이퍼바이저는 하드웨어 레벨에서 격리되므로 보안적으로는 하이퍼바이저가 우위에 있다.
MapReduce와 HDFS가 어떤식으로 결합해서 실행되는지 살펴보자. 특히 Hadoop 1.xx 버전에서는 이렇게 실행된다. 앞에 구글 MapReduce에서 master라고 했던 부분은 JobTracker라는 master processor로 Hadoop에서 실행되고, 구글 MapReduce의 Worker는 Hadoop에서 TaskTracker라는 slave processor로 실행된다. 기억을 더듬어 보면 HDFS에서 namenode라고 하는 master가 있어서 얘가 메타데이터(meta data)를 관리했고 datanode가 각각의 slave node에서 실행되면서 local Linux file system에 실제 애플리케이션 데이터를 관리하는 형태로 실행됐었다. 비슷하게 MapReduce가 실행되기 위해서는 Master processor인 JobTracker, 그러니까 job을 제출하는 job submission node에서 JobTracker가 실행돼야하고 각각의 slave node에서 tasktracker보다는 slave process가 실행되어야 한다. 그러니까 namenode, datanode가 hdfs에서 cluster를 구성하는 것이고 JobTracker와 tasktracker가 MapReduce 프레임워크를 구성하고 있다고 보면 된다. namenode와 job submission node를 하나로 묶는 경우도 있고 기계가 남아돌면 분리 하는 경우도 있다.
Slave node를 물리적인 노드를 의미한다고 생각하면 된다. 각각의 물리노드에 hdfs를 위한 datanode daemon과 MapReduce를 위한 tasktracker를 모두 실행되고 있는 것을 볼 수 있다. 왜 이렇게 실행 되어야 하냐면 만약 둘 중 하나가 빠져있으면 문제가 생긴다. 정확히 말하면 MapReduce를 처리할 때 문제가 생길 수 있는데, 예를 들어서 한 slave node에 tasktracker가 없다고 치고, datanode는 다 돌고 있다고 하자. 그러면 job submission node에 있는 JobTracker가 tasktracker가 없는 노드로는 map task나 reduce task를 보낼 수 없다. Task tracker가 실제로 JobTracker의 명령을 받아서 map 또는 reduce task를 실행하는 주체이기 때문에 tasktracker가 없다고 하는것은 task를 실행할 수 없는 것이기 때문에 Mapeduce 프레임워크 입장에서 봤을때는 해당 slave node가 없는 것과 같은 맥락이다.
반대로 tasktracker가 있는데 datanode가 안돌고 있다고 하면 어떻게 될까? 그렇게 되면 해당 slave node는 namenode에게 눈에 보이지 않는 것이다. 즉 해당 slave node는 없는 것과 마찬가지이다. 그래서 datanode와 tasktracker는 항상 같은 노드에서 실행이 되어야 한다.
ps. Hadoop yarn에서도같은맥락에서동작한다.
Hadoop job processing step
MapReduce job processing의 step을 그림으로 살펴보자.
Run job : client가 job을 실행해 달라고 JobClient 클래스에 요청을 한다.
Get new job ID : 새로운 job ID를 JobTracker에게 요청해서 job ID를 받게된다.
Copy job resources : job에 관련된 resource들을 shared file system에 업로드한다. (Job resource라고 하는 것은 보통은 mapper와 reduce 클래스 다 포함하고 있는 jar 파일 같은 것이다. Jar 파일 같은것들을 hdfs에 올려놓아야 나중에 MapTask나 ReduceTask를 실행할 수 있게 된다. 왜냐하면 MapReduce job을 submission 하면은 실제 Map과 Reduce가 어디서 실행 되냐면은 전적으로 JobTracker가 알아서 한다. 이 얘기는 MapReduce job의 map task와 reduce task가 Hadoop cluster를 구성하는 어느 node에서 실행될지 모른다. 사전에 알면 그 노드에 필요한 파일들을 갖다놓을것이다. 그러나 안된다. 어디서나 접근이 가능한, 모든 노드에서 접근을 할 수 있는 file system이 대표적으로 hdfs이기 때문이다.)
Submit job : job을 제출한다.
Initialize job : JobTracker가 initialize 한다.
retrieve input splits : input split은 MapReduce job이 처리하고싶은 단위이다. 그러니까 64mb씩 쪼개서 각각의 input split에 대해서 어느 tasktracker에 있는지 찾아내야한다. 그래야 각각에 대한 input split에 mapper를 띄울 때 최대한 그 데이터에 가깝게 스케쥴링 할 수 있기 때문이다.
Heartbeat : input split을 기반으로 해서 tasktracker에게 작업을 할당하게 되면 주기적으로 heartbeat을 보내게된다.
Retrieve job : tasktracker는 child JVM을 launch시켜서 Map 또는 Reduce task를 실행하게 되는데 그 전에 해야할게 HDFS에 접근해서 job resource(jar 파일 같은거)를 받아와야한다. jar파일 같은게 로컬하게 있어야 map/reduce task를 실행시킬수있다.
JobTracker가 하는 가장 중요한 일은 기본적으로 cluster에 있는 특정 노드들의 MapReduce task들을 경작(farm out) 하는 것이다. (task는 job을 이루는 구성요소) (MapReduce task는 map task + reduce task를 말한다) input data를 갖고있는 그 노드에 map task를 가져다 주거나 적어도 같은 rack에 있는 노드에서 map task를 실행해서 같은 rack에 있는 데이터 노드를 복사해올 수 있게한다. 이것은 data locality에 해당된다.
Data locality를 구현하는 주체는 JobTracker이다.
그런데 JobTracker라고 하는 것은 single point of failure이다. (단일고장점) 만약 JobTracker가 죽게되면 모든 실행중인 MapReduce job은 멈추게(halting) 될 수 밖에 없다.
많은 사람들의 job을 관리해야 하니까 JobTracker가 가지는 overhead는 클 수 밖에 없다. 수많은 task에서 state정보를 메모리에서 계속 관리하고 있기 때문에 너무 자주업데이트 된다. 회사로 예를 들면 부서별로 JobTracker가 따로돌면 관리부담도 줄어들고 좋다. 이런 부담을 도입해서 Hadoop2에서는 yarn이라는 운영체제가 나오면서 apllication master라는 대체개념이 나온다.
그 이후 JobTracker가 최대한 가깝게 스케쥴링을 해야하니까 기본적으로 input data가 있는 위치를 물어보기 위해 namenode랑 컨택한다. (JobTracker는 프로세싱만 하고 데이터관리는 안한다)
namenode로 부터 받아서 그 노드들 중에 최대한 input data랑 가깝게 있는 tasktracker node를 찾는데 (가용한 slot이 있는 경우)
TaskTracker를 찾으면 TaskTracker node들 한테 일을준다.
TaskTracker node들이 기본적으로 모니터링된다. Data node와 namenode처럼 heartbeat을 주고받는다. (분산시스템에서 서로의 생사를 확인할 수 있는 방법은 구글처럼 master가 ping을 하던지, 하둡에서 slave가 주기적으로 heartbeat을 보내주던지 이 두개밖에 없다) 만약에 heartbeat을 받지 않으면 다른 그 작업을 다른 tasktracker한테 스케쥴링 하게 된다.
자기가 실행하고 있는 task가 에러가 나면서 죽으면 JobTracker에게 알려준다. Jobtracker가 fail난 task를 다시 다른곳에 resubmission 한다. 이것은 혹시라도 그 tasktracker가 실행되는 node의 환경이 맞지 않아서 task가 죽은 것일수도 있으니까 다른곳에서도 해보는 것이다.(계속 죽으면 블랙리스트에 넣는다)
전체적인 작업이 끝났다. 이 얘기는 MapReduce작업이 끝났다는 얘기이다.
그러면 client apllication이 JobTracker한테 관련된 정보를 가져올 수 있게되는 형태로 진행된다.
MapReduce의 progress는기본적으로 JobTracker가담당한다고보면된다.
TaskTracker
TaskTracker라고 하는 것은 기본적으로 map, reduce, shuffling과정이 있었는데 이러한 task들을 jobtracker한테 받아서 실행하는 역할을 수행한다. 그런데 shuffling task라는 것은 reduce task가 remote procedure call을 통해서 map task가 실행됐던 그 node의 데이터를 복사해 가는거니까 조금 다른데 map과 reduce같은 경우에는 slot이 정해져 있다. 각각의 TaskTracker 같은 경우는 slot이 정적으로 설정되어 있다. 동적으로 실행시간이 변하는게 아니다. 각각의 TaskTracker가 받아들일 수 있는 mapper 또는 reduce의 개수가 사전에 구성이 되어있다 라고 이해하면된다. Static configuration의 문제는 뭐냐면 결과적으로 Hadoop cluster가 homogenous하다고 가정하는 것이다. node의 하드웨어 스펙이 비슷하니까 각자 균등하게 분할해서 똑같은 숫자의 Mapper와 똑같은 숫자의 reduce를 처리하면 되겠네 라고 하는 naive한 방식으로 시작한 것이다. hadoop이 탄생할 때 이런 모습이고 목적이었는데, 시간이 지날수록 하드웨어 자원이 발전하니까 각각의 노드의 컴퓨팅 파워가 달라지기 시작하고, 문제가 뭐냐면 hadoop 생태계가 커지면서 MapReduce말고도 다른 형태의 프레임워크가 들어오기 시작했다. 이런것들 때문에 고정적인 slot기반의 자원관리가 좋지 않다. (slot의 단점)
각각의 TaskTracker는 separate JVM process를 낳아서(spawn해서) 실제 일(actual work)을 한다. Separate JVM을 launch하는 이유는 map이나 reduce task가 실행되다가 죽더라도 tasktacker자체는 별로 영향을 미치지 않게 하기 위한 것이다.
그래서 spawning된 프로세서를 TaskTracker는 꾸준히 모니터링 하면서 output과 exit코드를 캡쳐 해서 jobtracker한테 보고하게 된다.
프로세서가 끝나게 되면은(성공적으로 끝났던, 중간에 에러나서 죽었던) 이 결과를 기본적으로 jobtracker한테 보고(notification)하고 다음 지침을 받는다. 그리고 중요한 것은 각각의 TaskTracker들은 jobtracker한테 주기적으로 heartbeat message를 보낸다. (TaskTracker가 살아있음을 계속 알림)
각각의 TaskTracker가 주기적으로 heartbeat을 보내면서 현재 가용한 slot의 개수를 알려준다. 그러면 jobtracker는 이 cluster를 구성하는 전체 TaskTracker의 가용한 slot들을 다 알고 있는 것이된다. 그러면 새로운 MapReduce job이 들어와서 task assign을 할 때 그 slot들을 보면서 결정하는 것이다. 고려해야 할 것이 두 가지이다.
구글이 디자인한 MapReduce에서 Fault Tolerance는 어떻게 해결하는가이다.
Hdfs를 기억해보면 datanode가 namenode한테 주기적으로 heartbeat을 보냈다. 구글이 구현한 MapReduce같은 경우에는 master가 주기적으로 ping한다. 분산시스템에서 node의 failure를 detect하는 방법은 주기적인 메시지교환 밖에 없다.
master가 어떤 worker가 죽은것을 알았을 때, 그 map task를 reset해서 다른 worker에서 다시 돌린다. 그러면 complete된 map task는 failure가 일어나면 재실행(re execute) 되는건데, 왜그럴까요? 각각의 mapper가 생산해낸 중간결과물(Intermediate key value)은 어디있죠? 그 mapper가 실행되는 그 node의 로컬디스크에 저장되어있다. 당연히 fail했다는 의미는 로컬디스크에 접근이 안된다. 결과적으로 봤을 때 failure를 detect했을 때, 거기에 할당되는 모든 map task들은 다시 실행된다.
반면에, reduce task가끝난다음에죽었다. 그러면얘네들을굳이다시실행할필요가없다. 왜냐하면 reduce task의결과는항상 global file system, hadoop으로따지면 hdfs에저장되기때문에그노드에저장되는것이아니라안정적으로접근이가능하다. (이미그노드를떠난것이다. ) 의문을가질수있는게 Intermediate key/value pair들도 hdfs에저장해두면다시실행할필요가없는데, 구글디자이너들이생각할때 intermediate data까지 global file system에저장하는것은아니다고생각했다. 왜냐하면 intermediate 라는의미는어차피사라질데이터이기때문이다. (reduce가끝나고나면중간결과물이필요없어진다)
(Resilient)
실제로 구글에서 80개의 머신이 죽었는데 살아있는 것들 위주로 작업을 재실행 하면서 진행했다. 결과적으로 전체적인 MapReduce 작업을 무사히 끝마칠 수 있었다.
Network bandwidth자체가무한대자원이아니라항상부족할수있는자원이다. 그러다보니이걸조금아껴써야하지않나고생각하며디자인철학이생겼다. (일반적인 commodity computer 환경에서) hdfs는 block단위로쪼개서데이터노드들의로컬디스크에각각다저장이되어있다. 그러면그냥로컬디스크에있는데이터를읽게하는것이좋겠다라고생각하는것이죠. 그래서 “Moving computations close to the data”라는개념이나왔다. 기존의슈퍼컴은데이터를 computing 쪽으로보내는모델이었는데이렇게하지말고데이터를이미분산시켜놓은다음에거기에 computation (MapReduce관점에서 mapper)로보내면되겠다고고민했다. 그래서구글 mapreduce에서 master는 map task를필요로하는 input split 데이터를실제로소유하고있는 machine에 allocation하기위해최선을다한다. 만약에그것을실패하게되면그노드가바빠서더이상작업을받아들이지못할수도있으니까, 그러면그나마 input data 가까이에배치하고싶어한다.
가깝다는 개념은 hdfs에서도 다루었다.
Data block과 최대한 가깝게 보낸다고 하는 것은, Node-2를 보면 저기 map task가 원하는 input split(data block)이 같이 있는 것이다. 이것을 data와 computation을 colocation 시킨다라고 표현했다. 이런 경우를 “data local”이라고 표현한다. Data local인 경우가 best case이다. 최적의 상황이다. 왜냐하면 여기서는 network 통신이 일어나지 않기 때문이다.(network bandwidth를 아낄 수 있음)
만약에 Node-2처럼 이런 환경을 만들어낼 수 없다면, “rack local”도 생각할 수 있다. Node-3의 map task가 원하는 input split이 Node-4에 저장이 되어있다. 이런 경우에는 같은 Rack-1에 있는 다른 노드(node)의 데이터를 copy하는 것이 낫겠다고 생각하게 되는것이죠. 이것이 rack local이다. 그러나 data local, rack lock 둘 다 안되는 Node-5를 보면 다른 rack에서 copy해와서 실행한다.
hdfs의블록배치방법이 mapreduce의블록배치에도도움이되었다.
Large-Scale Indexing
구글이 mapreduce를 개발해서 여러 분야에 했었는데, 그 중 대표적인 것이 Large-Scale Indexing이다. 검색엔진을 만들어야 하니까 index를 만들어야 했다.
빅데이터를다루는데있어서분산시스템은피해갈수없는숙명같은것이다. 왜냐하면, 단일노드(단일컴퓨터)에서는처리할수없기때문에, 클라우드환경에서빅데이터분석(big data analytics)을할때는반드시분산된시스템에서할수밖에없는것이고, 그랬을때개발자(사용자)입장에서좀더쉬운 API를통해서그들이풀고자하는문제에집중하게해주고나머지는플랫폼(시스템)이처리해주는이런모델로가고있다고보면된다.
MapReduce의 programming model은 기본적으로 input key/value pair를 받아들여서 output key/value pair를 생성하는 형태로 pipeline처럼 연결된다. Map이 처음 시작할 때도, 처리해야하는 input data를 key/value형태로 받아들이며 Map이 역시나 key/value 형태로 내보내게 된다. 그러면 내보낸 intermediate key/value pair들이 결국 그룹핑(grouping) 되면서 key/value들의 리스트 형태로 Reduce로 넘어간다고 보면 된다. 결국 Reduce도 마찬가지이지만 Map이라고 하는 함수는 사용자가 작성을 해야한다.
입력데이터가 하나의 노드에서 돌리면 상관이 없는데, 이 데이터의 용량이 수백 기가, 혹은 테라바이트면 하나의 노드 에서는 어려울 수 있다. 그렇게 되면은 hdfs에서 정한 64mb 블록사이즈로 쪼개서 저장한 다음에 MapReduce가 블록 단위로 처리하게 된 것이다.
Splitting:
이것을 input split이라고 얘기한다. MapReduce관점에서는 처리하고자 하는 입력데이터의 단위이기 때문에 input split이라는 명령어를 쓰는 것이고 hdfs관점에서는 데이터가 저장되는 단위이기 때문에 block이라는 개념을 쓴다. 엄밀하게 말하면 input split과 block이 꼭 같은 사이즈일 필요는 없다. 예를 들어서 데이터가 저장되어 있는 것은 64mb block 단위로 저장되어 있는데 하나의 input split, 하나의 mapper가 처리하고자 하는 데이터양이 두개 이상의 block을 한꺼번에 처리하고 싶다던가, 이런 것도 가능하다. 그런데 이렇게 했을때는 성능상에 이점이 없기 때문에 input split과 hdfs block사이즈를 맞추게 된다. 왜 이렇게 하는지는 나중에 설명이 나온다. 그러니까 한줄 한줄이 input split이다. MapReduce가 입력 데이터를 처리하는 단위이다.
Mapping:
mapper가 세 개가 떴다고 생각하면 된다. Mapper가 세 개가 떴으면 mapper는 자기가 담당하는 input split을 읽어들여서 사용자가 정의한 map함수를 적용한다. 그런데 사용자는 어떤 식으로 구현한거냐면 (splitting 단계에 있는 것을) 한줄씩 읽어서 파싱(parsing)한 다음에 단어별로 뽑아낸다. 단어를 key로 잡으면 이것이 intermediate key가 된다. 그리고 value는 1이다. 정리하자면 input split을 logical record 단위로 한줄씩 읽으며 파싱한 다음에 거기에서 나온 단어(word)를 key로 잡고 1을 value로 내보내면 되겠다고 인지할 수 있다. 결론적으로 이 단계에 있는 9개의 key/value들이 intermediate key/value pair들의 집합이다. 중요한 포인트는 mapper들이 intermediate key/value pair들을 모두 생산해 낼 때 까지는 reduce 단계로 넘어가지 않는다. 나중에 오는 것들 중에서 집계가 덜 된 데이터들도 있을 수 있기 때문에 mapping단계가 끝날 때 까지 기다린다. 그 다음에 shuffling 단계로 들어간다.
Shuffling:
reduce단계로 넘어가기 위해서 shuffling 단계로 넘어간다. 이 단계에서는 기본적으로 intermediate key를 공유하는 value들을 묶이게 되는 것이다. 다시 말해 동일한 intermediate key를 공유하는 value들이 묶이고 이 value들이 리스트 형태로 넘어가게 된다. 그래서 예를 들어 [1,1]에서 1 + 1 이런식으로 해서 나온 값을 넘겨준다.(aggregation 연산을 수행할 수 있게 된다.) 그래서 Reduce단계에서 같은 키를 갖는 value들은 항상 똑같은 reducer로 간다.
Reducing:
reduce에서 사용자가 정해놓은 함수가 있을것이다. 같은 key를 공유하는 value들의 리스트가 무더기로 넘어올 때 더하는 식으로 만들었다. 그럼 final result를 이제 글로벌하게 입력파일이 있을 때 전체적으로 저렇게 나온다.
MapReduce의 가장 큰 장점은 이 플로우를 생각해서 maper와 reducer를 개발한다고 치자, input을 어떻게 받을거고 output 내보낼 것이고 reducer단계에서는 어떤식으로 결합할 것이라고 정했다고 생각하면, 입력데이터가 아무리 크다고 하더라도 MapReduce는 소스코드 수정없이 모든 데이터 처리를 성공적으로 수행할 것이다. 결론적으로 인풋의 크기가 전혀 상관이 없다는 얘기이다. 이것이 가능한 이유는 mapper가 실행되는 단계에서는 각 input split별로 동시다발적이면서 독립적으로 실행되는 것이다. 그리고 모든 매핑이 끝난 다음에 셔플링과 리듀싱 단계로 넘어가기 때문이다.
즁요한 것은 intermediate key/value pair를 어떻게 잡을 것이냐 이다.
Mapreduce processing 하는 것은 데이터를 처리해서 insight를 얻기 위함이다. 그리고분산되어있는큰데이터들을어떻게하면빠르게병렬처리하고높은 through put 을낼수있는것을고민한결과이다. 그리고기본적인빅데이터처리모델이다.
그전 포스트에서는하둡(Hadoop)이빅데이터를어떻게저장하는지에대해배웠고이제는분산파일시스템에저장되어있는데이터를어떻게하면효율적으로병렬처리할수있으면서전체적인 through put을높일수있는방안에대해고민한 MapReduce 프레임워크에대해서살펴볼것이다.
Hadoop project라고 하는 것은 distributed file system이고 very large data set을 analysis 하고 transformation 할 수 있는 MapReduce라고 하는 페러다임을 가지고 있다. 사실은 MapReduce라고 하는 것은 클라우드 프로그램밍 모델인 동시에 runtime system이라고 할 수 있다. 그래서 데이터만 partitioning 하는 것이 아니라 computation도 분할해서 수천개 이상의 호스트들에게 분산해서 실행하는 것이다. 즉 분산돼서 데이터도 저장하고 분산해서 실행하는 것이다.
MapReduce의 큰 특징중 하나는 애플리케이션에 computation(task 어떤 분산시스템에 작업단위를 job이라고 표현했다)들이 되도록 병렬하게 동시다발적으로 실행될 수 있도록 하므로써 전체적인 시스템에 성능을 높인다. 데이터와 최대한 가깝게 처리하고 싶은 것이 MapReduce의 목적이다. 데이터와 가깝다는 것은 data locality 장점을 보는 것이다. 가깝다는 것을 어떻게 표현했냐면, 같은 노드에 있으면 distance가 0였고 다른 노드라고 하더라도 똑같은 rack에 속해있으면 distance가 2다. 그리고 rack마다 달라지면 distance가 4로 늘어난다 이런식으로 표현한다.
MapReduce라고하는것은프로그래밍모델이다. 왜프로그래밍모델이라고하냐면모든 computation을 Map과 Reduce라고하는두개의함수로만표현하기때문에프로그래밍할수있는일종의범위(scope)을확줄여놓았다. 이런관점에서보면은프로그래밍모델이다라고말할수있다. 또한이와관련된구현결과물인데어디에대한결과물이냐면, 굉장히대용량의데이터를처리하고생산해낼수있는, MapReduce의결과로다른데이터가생성될수있다. 이런목적으로탄생한프레임워크가바로 MapReduce이다. 왜 Map과 Reduce냐면, 개발자는 Map function과 reduce function을개발해야한다.(코딩해야한다) 이것은 MapReduce 프레임워크는사용자가정의해준 Map과 Reduce function을잘적용하는역할을수행하는것이지더많은책임을지는것은아니다. Map과 Reduce는특징이뭐냐면입력과결과가항상 key, value pair형태로표현하고이런표현으로통신하게된다.
MapReduce를 개발하게된 동기(motivation)을 살펴보자.
MapReduce를 개발하기 이전에는 어떤식으로 구글이 작업했는지에 대한 이야기를 해보자.
구글은 세계 최고의 검색엔진 회사이다. 그래서 구글이 웹 다큐먼트를 크롤링 해와서 상당히 raw data가 많이 쌓이고 이걸 통해서 여러가지 일들을 수행하는 회사인데, 구글이 MapReduce이전에 했던 것들을 보면, 특수목적형 계산 프로그램(special purpose computations)들 수백개를 계속 만들어왔다. 이런것들은 굉장히 큰 규모의 raw data들을 처리하는 것들인데 크롤링된 document라던지 웹 리퀘스트 로그(web request log)라던지 이런것들을 분석/처리해서 다양한 형태의 결과물(derived data)을 뽑아내는데, inverted index(inverted indices)라던지, 아니면 web document를 그레프(그래프 graph) 형태로 표현한다든지, 아니면 호스트당 크롤링된 페이지의 통계를 구한다던지, 아니면 하루에 가장 자주 들어온 query를 찾아낸다던지 이런 여러가지 일을 한다.
이렇게 수행이 되고 있었는데 문제가 뭐였냐 하면,
구글이대용량의 raw data를처리하기위해서이런개발물들(computations)자체가개념적으로그렇게어려운것이아니다(conceptually straightforward)이다. 그런데입력(input) 데이터가매우크다그리고어느정도감내할만한시간내에끝내게하려면수백수천대이상의머신에분산되어서 computation이실행되어야한다. 어쩔수없는것이다. 데이터가너무많다보니까이거를하나의노드에서처리한다는것은불가능하기때문이다. Hdfs때많이얘기했지만, 결국은분산파일시스템자체가데이터가한노드에다저장되지못하기때문에나온것이기때문이다. 마찬가지로 computation 계산과정에서봐도데이터가너무크면분산처리할수밖에없다. 그러니까구글이하고자하는일들이아주복잡한형태는아니었음에도불구하고 input data가너무커서 computation을분산시키다보니까분산컴퓨팅(distributed computing)으로인한 overhead가너무컸던것이다. 어떤오버헤드(overhead)가있냐면, hdfs에서도다루었지만일단분산시키는순간 failure가가장문제가된다. 노드가죽거나한참열심히실행하다가노드가죽으면어떡하지? 그리고특히프로세싱측면에서봤을때는로드벨런싱(load balancing)도굉장히어려운문제이다. 무슨얘기이냐면, 내가열개의노드에열심히분산시켜서실행하고있는데어떤 1~2 노드가성능이딸려서그런건지늦게실행이되면은전체적인프로세스에영향을받는다. 그런관점에서봤을때구글도분산처리를관리하는데상당히힘들었던것이다. 이것을좀더편리하게할수없을까? 뭔가추상화레벨을높여서 run time system 이런것들을해주면좋겠는데라는어려움이있었기때문에map reduce라고하는프로그래밍모델인동시에관련된구현결과물(run time system)인새로운프레임워크가구글에서탄생하게되었다고보면된다.
Map Reduce는 프로그래밍 모델인 동시에 구현결과물(runtime system)인데, large data set을 생성하고 처리하는데 사용되는 것이다.
그래서 MapReduce라고 하는 것은 결과적으로 단순한 형태의 computation을 어떻게 하면 잘 표현할 수 있을까 추상화를 고민하는 것이다. 구글이 하고자하는 대용량의 raw data를 처리하는 많은 작업들(computation)의 특징이 뭐였냐면, conceptually straightfoward 한것이다. 개념상으로는 아주 어려운 문제를 푸는 것임이 아니었음에도 불구하고 단순히 input데이터가 너무 크기때문에 분산처리하는 영역이 있는 것이다.
그래서 추상화를 하면서 어떻게 하느냐면, 분산처리를 하다보면 messy한 디테일들인 병렬화(parallelization), 고장 감내(fault tolerance), 데이터를 어떻게 분산시킬것인가(data distribution) and 로드벨런스(load balancing) 이런것들을 처리해야 한다. 즉 정리하자면 simple한 computation을 잘 표현할 수 있는 길을 열어주고 parallelization, fault tolerance같이 분산처리 하면서 발생할 수 있는 messy한 문제들을 개발자로 부터 감춰주면 좋겠다.(감춰준다는 의미는 사용자가 직접 하는 것이 아닌 분산처리 문제는 MapReduce가 알아서 해준다는 의미) 사용자가 풀고자 하는 문제를 Map과 Reduce에 맞게 개발하면 된다는 것이 MapReduce의 철학이다.
MapReduce는 Lisp라고 하는 functional language에서 있던 Map과 Reduce라고 하는 개념을 가져온 것이다.
그래서 첫번째 단계에서 map이라는 operation은 사용자가 정의해줘야 하는 것이다.(틀만 있다) 각각의 record에 대해서 map operation을 적용하고, 적용한 결과로 뭐가 나오냐면 intermediate key/value pair가 생성된다. 즉 map과 reduce에서는 항상 input과 output에서 key/value로 통신한다. record라고 하면 데이터베이스에서 튜플이다. mapreduce에서 말하는 데이터는 주로 비정형 데이터이기 때문에 텍스트 문서의 한줄한줄을 logical record라고 생각하면 된다.(거기 어떤 내용이 들어있던 상관없이) 사용자가 정의한 logical record를 읽어서 사용자가 정의한 map function을 적용하면 결과물로써 intermediate key/value pair가 생성된다.
이러면 reduce단계로 넘어가야 하는데 reduce라고 하는 것은 aggregation 연산을 수행하게 되는데 map과 reduce중간에 shuffling이라는 단계가 들어간다. shuffling이라고 하는 것은 map reduce 프레임워크가 알아서 해주는 것인데,
뭘 헤주냐면, 같은 키를 공유하는 모든 value들을 묶어준다. 다시 말해 intermediate key/value pair중에서 같은 키값을 갖는 value들은 다 왕창 묶어준다는 얘기이다. 제대로된 aggregation 연산이 이루어 진다고 볼 수 있는 예시가 wordcount 문제였다. 같은 키를 공유하는 value들의 리스트를 받아서어떤형태로든 combine 연산을 수행하면 되는 것이다. shuffling에서 중요한 부분은 뭐냐면 같은 키를 공유하는 value들은 반드시 한꺼번에 묶여서 온다는 것이다. key가 같은데 value 들의 set이 분할될 수는 없다는 것이 철학이다. 만약에 분할이 되면 최종 통계를 낼 때 할 수 가 없다. 그러니까 반드시 같은 중간 키값을 공유하는 모든 value들은 하나의 reducer로 전달되게 된다. reducer가 전체시스템 하나라면 문제가 없겠지만 두 개 이상이 될 경우에는 두 개의 reducer에분할돼서 같의 집은 key를 갖는 value들합이 쪼개지면 결코 안되는 것이고 이것은 MapReduce프로그램이 guarantee해준다.
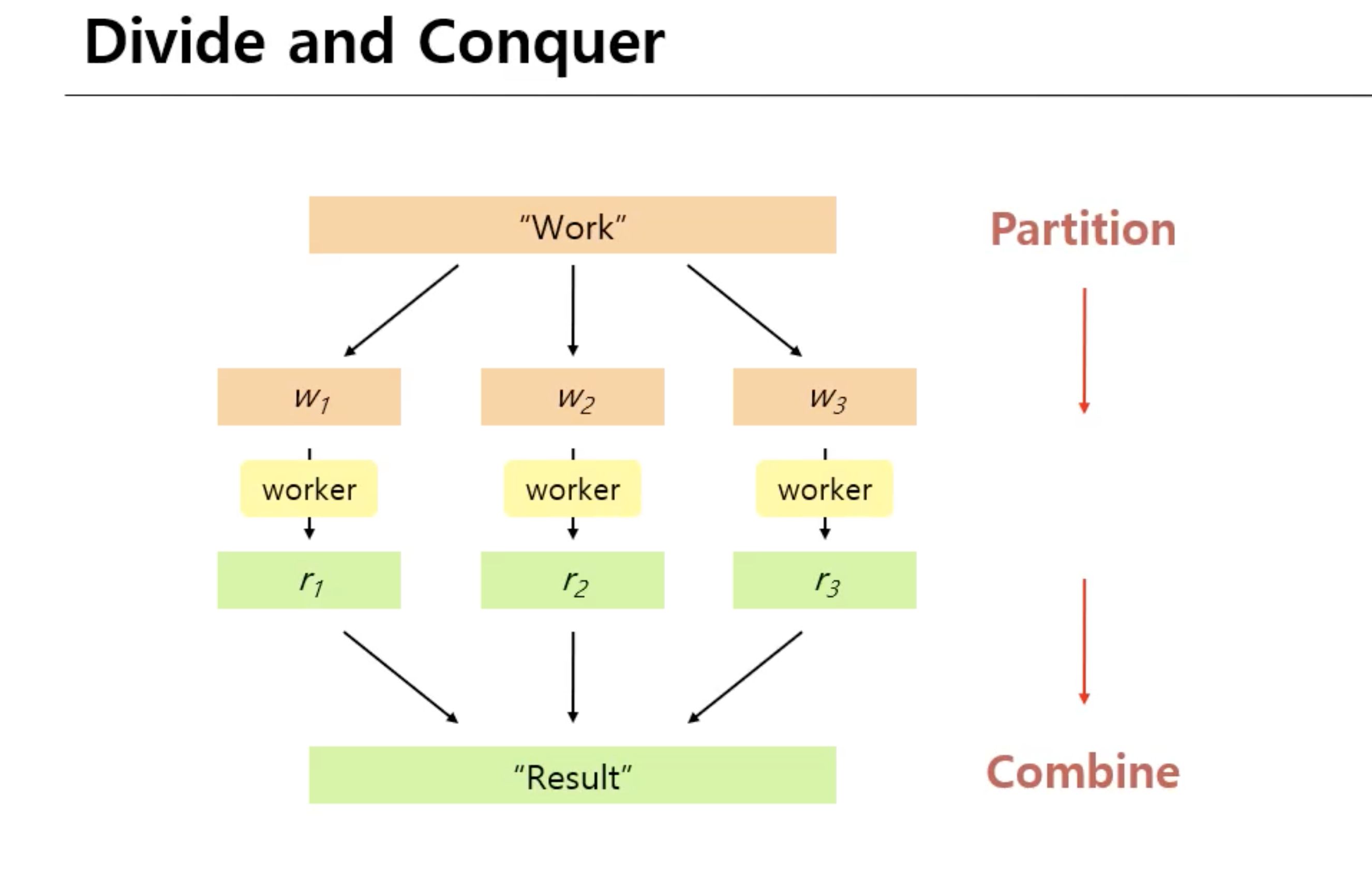
빅데이터를 다룰 때 가장 좋은 방법은 divide and conquer방식 이다. 딥러닝 같은 계산이 많은 것들과 같이 문제의 사이즈가 커지면 할 수 있는 방법이다. 하나의 work를 좀 더 세부적인 work로 쪼갠 다음에 작업을 처리하는 worker( = 프로세스, 노드 등등 작업을 실행하는 주체)들을 동시다발적으로 병렬 실행을 하고 그 결과를 취합을 해서 conbine하는 과정으로 빅데이터 문제 또는 big compute 문제를 다룰 수 있게 된다.
Parallelization Challenges
How do we assign work units to workers?
작업분배가문제가될수있는것은, 똑같은 work 유닛이라하더라도재수가없으면실행시간이오래걸릴수있기때문에 work 유닛을잘결정하는것이중요한문제가된다.
What if we have more work units than workers?
worker들보다작업이더많을때, worker들을사용할수있는자원이 100이라고해도 work 유닛자체가 10000이면, 이래나저래나 worker들이작업을다수행할때까지는병렬적으로실행을해야할때, worker들간에어떻게작업분배를최적화할것인가가문제이고이것이 load-balancing 문제이다. Load balancing이라고하는것은어떤하나의 worker가너무많은작업을처리하면, 그것때문에전체적으로프로세싱이느려지기때문이다. 왜냐하면모든 worker가작업이끝나야최종적인결과가나오는데한두명의 worker가느려지면그만큼최종결과물이늦게나오기때문이다.
What if workers need to share partial results?
worker들이중간결과물을교환해야할때어떤방식으로교환할건지문제가된다.
How do we aggregate partial results?
중간결과물을어떻게합칠것인가가문제가될수있다.
How do we know all the workers have finished?
모든 worker들이실행이끝나야지만되는건데, 얘네들이끝난지어떻게알수있을까가문제이다. 끝났으면연락을하던가알람을뜨게하던가여러가지방법이있을수있다.
Virtual machine이 있었기 때문에 앞의 디즈니 사례에서 갑자기 20분안에 필요한 4만 core를 준비할 수 있었다. 물리적인 기계들을 20분만에 사지 못하기 때문이다. 자원을 재빠르게 필요로 하는 어플리케이션에게 충분한 양의 자원을 제공할 수 있는 길을 열었다.
왼쪽의 컴퓨터는 하드웨어에 운영체제가 하나고 그 위에 어플리케이션이 돌아간다.
그러나
오른쪽은 Virtualized Stack을보면 Hypervisor위에여러개의 OS가있을수있다. 결과적으로봤을때하나의물리적인자원에서구동할수있는운영체제의종류도다양해진다는것은하나의물리적인자원을최대한잘공유해서여러개의운영체제가공존할수있도록만든것이 Hypervisor 기술이다.
Type 2 hypervisor인 경우, Hypervisor는 App1과 App2와 같은 레벨에서 동작하고 하이퍼바이저 위에서 또다른 게스트 운영체제를 구축할 수 있다.
Type 1 hypervisor인 경우, 하드웨어 위에 바로 하이퍼바이저가 올라가고 그 위에 게스트 OS가 올라가는 것이다. 이것을 다른말로 bare-metal hypervisor(bare metal)이다.
결론적으로, Type1과 Type2의 가장 큰 차이는 host 운영체제가 있느냐 없느냐의 차이고, Type1같은 경우는 하이퍼바이저가 일정부분 호스트 운영체제를 수행한다고 봐도 된다. 그러면 뭐가 제일 다르냐면 Type1 같은 경우에는 데이터센터에 들어가는 서버에서 많이 사용되는 bare metal hypervisor이다. 왜냐하면 개인용 pc이나 노트북 같은 경우에는 드라이버 같은 경우에는 다양할 수 있다. 그러니까 호스트 운영체제가 담당을 해주고 그 위에 하이퍼바이저를 올리는게 하이퍼바이저 입장에서도 부담이 적다. 디바이스를 접근할 때 호스트 운영체제의 도움을 받으면 되는데 만약에 type1처럼 하면 모든 디바이스를 하이퍼바이저가 어느정도 컨트롤할 수 밖에 없다. 서버같은 경우에는 컴퓨팅 자원이기 때문에 설치되는 디바이스들이 다양하지 않아서 상대적으로 관리하기 편하다. 그래서 type1인 bare metal hypervisor 같은 경우에는 서버급에 많이 사용되는 가상화 기술이다. 보통 사용자들(노트북, 퍼스널 컴퓨터)은 type2를 사용한다.
type1같은 경우는, 별도의 작업 없이 컴퓨팅, storage만 하기 때문에 hypervisor가 관리해야하는 주변기기 장치가 다양하지 않기 때문에 상대적으로 하드웨어 위에서 컨트롤이 가능하다. 그래서 이 타입은 데이터센터에 들어가는 서버용이다.
반면, type2같은 경우는, 퍼스널 컴퓨터나 노트북은 다양한 어플리케이션을 돌린다. 그러기 때문에 호스트 운영체제에 의존하면 된다. 왜냐하면 어차피 호스트 운영체제가 구동되는 상황이면 호스트 운영체제가 모든 자원을 컨트롤 하고 있으니까 이것을 통해서 접근하면 된다. 그래서 이 타입은 범용적인 못적으로 사용한다.
맥북 같은 경우는 Mac os위에 parallelize가 hypervisor위에 올라가고 그 위에 윈도우 같은 것을 구동시킨다.
Hypervisor는 하드웨어로 부터 추상화 개념을 제공하는 소프트웨어이다. 왜냐하면 물리적인 하드웨어를 추상화 시켜서 게스트 운영체제에 다 전달할 수 있기 때문이다.
초기에는 작업이 없다가 중반으로 갈때는 점점 작업이 많아지는데, 작업이 없을때는 클라우드 자원을 조금 쓰다가 작업이 많이 필요하면 많이쓰면 수요와 공급이 맞아떨어지면서 굉장히 효율적인 자원운용이 된다. 관건은 비용이다.
On-premises capacity의 문제는 처음에 사용하지 않을 때는 capacity가 남아돈다. 어떻게 생각하면 낭비가 되는 것이다. 중반쯤 되면 작업량이 많아지면 on-premises capacity를 넘어가게되고 밀려서 deadline에 가까워진다. 그런데 파란색 선 처럼 클라우드가 요구하는 만큼 자원을 계속 공급해줄 수 있다면 끝나는 시간을 왼쪽으로 땡길 수 있다. 작업을 빨리 끝낼 수 있게 scalable한 작업을 제공한다. 디즈니는 4만개의 cpu core를 20분만에 실행 시킬 수 있었다.
이러한 elasticity와 scalability를구현하기위해서는물리머신만으로는될수없고반드시가상화기술을사용해야만한다.
여기서 말하는 빅데이터를 단순한 데이터를 말하기 보다는 빅데이터를 관리하고 저장하고 처리하는 기술들 까지 포함하는 그런 개념이다. 빅데이터 기술을 사용하는 것이 왜 중요하냐 라고 했을 때, Big Data Analystics라고 하는 것은 조직들이 그들의 데이터를 효율적으로 활용하고 활용해서 새로운 기회를 식별해내는데 도움을 줄 수 있기 때문에 빅데이터 분석은 중요하다.