728x90
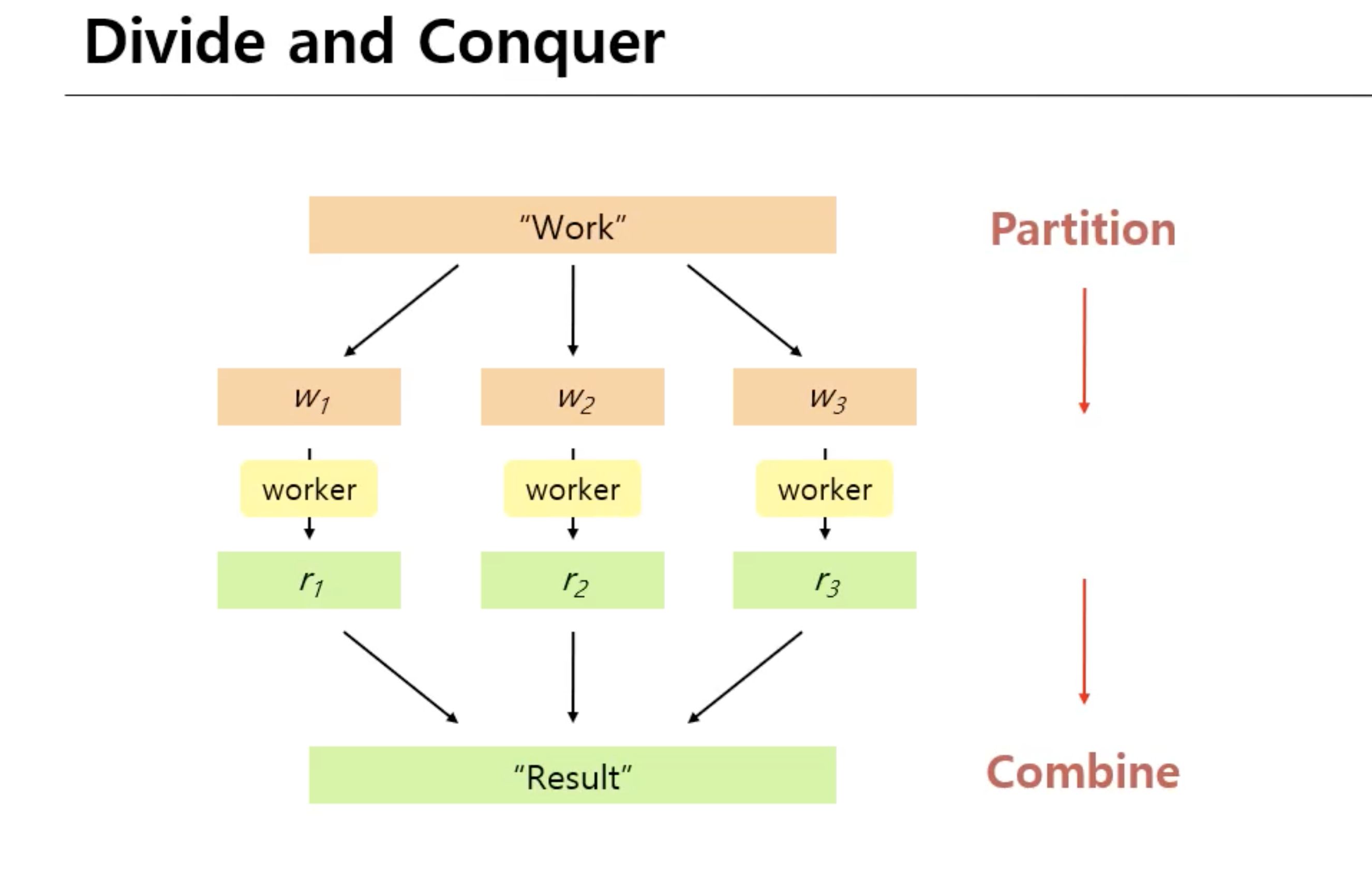
빅데이터를 다룰 때 가장 좋은 방법은 divide and conquer방식 이다. 딥러닝 같은 계산이 많은 것들과 같이 문제의 사이즈가 커지면 할 수 있는 방법이다. 하나의 work를 좀 더 세부적인 work로 쪼갠 다음에 작업을 처리하는 worker( = 프로세스, 노드 등등 작업을 실행하는 주체)들을 동시다발적으로 병렬 실행을 하고 그 결과를 취합을 해서 conbine하는 과정으로 빅데이터 문제 또는 big compute 문제를 다룰 수 있게 된다.
Parallelization Challenges
- How do we assign work units to workers?
- 작업분배가 문제가 될 수 있는것은, 똑같은 work 유닛이라 하더라도 재수가 없으면 실행시간이 오래걸릴 수 있기 때문에 work 유닛을 잘 결정하는 것이 중요한 문제가 된다.
- What if we have more work units than workers?
- worker들 보다 작업이 더 많을때, worker들을 사용할 수 있는 자원이 100이라고 해도 work 유닛 자체가 10000이면, 이래나 저래나 worker들이 작업을 다 수행할 때 까지는 병렬적으로 실행을 해야할 때, worker들 간에 어떻게 작업분배를 최적화 할 것인가가 문제이고 이것이 load-balancing 문제이다. Load balancing이라고 하는 것은 어떤 하나의 worker가 너무 많은 작업을 처리하면, 그것 때문에 전체적으로 프로세싱이 느려지기 때문이다. 왜냐하면 모든 worker가 작업이 끝나야 최종적인 결과가 나오는데 한 두명의 worker가 느려지면 그만큼 최종 결과물이 늦게 나오기 때문이다.
- What if workers need to share partial results?
- worker들이 중간 결과물을 교환해야할 때 어떤 방식으로 교환할건지 문제가 된다.
- How do we aggregate partial results?
- 중간 결과물을 어떻게 합칠 것인가가 문제가 될 수 있다.
- How do we know all the workers have finished?
- 모든 worker들이 실행이 끝나야지만 되는건데, 얘네들이 끝난지 어떻게 알 수 있을까가 문제이다. 끝났으면 연락을 하던가 알람을 뜨게 하던가 여러가지 방법이 있을 수 있다.
- What if workers die?
- worker들이 열심히 일 하다가 죽을 수 있다. 컴퓨터가 꺼진다거나 worker프로세싱이 실행하다가 죽을 수 있거나 이다.
위의 첼린지들로 봤을 때 병렬화(Parallelization)해서 뭔가 작업을 실행하는 것은 간단한 문제가 아니라는 것이다.
- Parallelization problems arise from
- parallelization 문제들이 무엇때문에 일어나는 것일까를 보면 주로 작업들을 실행하는 worker들이 서로 커뮤니케이션을 할 때 어려울 때 어려움이 발생한다. 예를들어, exchange state 또는 shared resources에 접근해서 뭔가 처리해야할 때 어려운 문제가 발생한다
- Thus, we need a synchronization mechanism
- 이 문제를 해결하기 위해, 어떤 식으로든 간에 동기화해서 서로 커뮤니케이션을 수행하고 공통된 지원에 접근할 수 있는 메커니즘이 필요하다.
- Concurrency(동시실행) is difficult to reason about
- concurrency가 논리적으로 어떤방식으로 흘러가는지 추론해내기가 쉽지 않다. 실행되다가 워커들이 죽거나 로드벨런싱이 문제가 될 수 있는 이유때문이다.
- Concurrency(동시실행) is even more difficult to reason about
- 단순히 10개 정도 되는 worker수준이 아니라 아에 데이터 센터 수준이 되거나 데이터센터 간에 하던가 할 때 병렬화 동시실행(Parallelization Concurrency) 하는것이 속도나 처리량(throughput)이 높아지겠지만 굉장히 어려워질 수 있고, failure가 일어날 수 있다. 그리고 서로 상호 맞물려있는 서비스가 있다면 Concurrency를 보장하기엔 어렵다.
- 디버깅 자체가 문제일 수도 있다. 로드벨런싱 문제인지 코드 문제인지, 환경이 문제인지 추론해내는 것 자체가 문제일 수 있다.
'서버 > 클라우드 컴퓨팅' 카테고리의 다른 글
| MapReduce: Programming Model (0) | 2021.12.16 |
|---|---|
| MapReduce (0) | 2021.12.16 |
| Cloud Computing & Big Data (0) | 2021.11.09 |
| 가상화(Virtualization) (0) | 2021.11.09 |
| Definition of Cloud Computing(클라우드 컴퓨팅의 정의) (0) | 2021.11.09 |