
728x90

onSubmitForm에 this를 출력해보면

리액트 내부가 나온다. 만약 “ this.onChangeInput = this.onChangeInput.bind(this); “를 주석처리 해보면
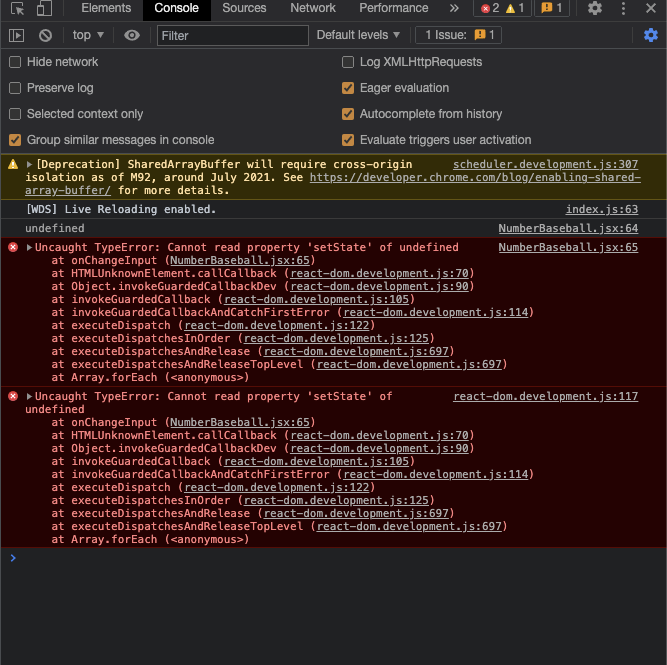
this가 undefined가 되는걸 볼 수 있다.
화살표 함수가 bind(this)를 자동으로 해주는 기능을 한다.
onSubmitForm = (e) => {
console.log(this.state.value);
}
최종적으로

화살표 함수를 사용하면 이렇게 편리하게 사용할 수 있다.
'프레임워크 > React' 카테고리의 다른 글
| [React] PureComponent와 shouldComponentUpdate (0) | 2021.07.23 |
|---|---|
| [React] 배열 (0) | 2021.07.22 |
| [React] map 다른 파일로 빼기 (0) | 2021.07.22 |
| [React] Map 사용법 (0) | 2021.07.22 |
| [React] webpack 설정들의 의미 (0) | 2021.07.09 |

















